I’m not well-versed in ML concepts, so this might be a very naïve question. I have followed the hyperparam tuning example here: Model hyperparameter tuning with scVI — scvi-tools
and applied the approach to my model. I used “validation_loss” as the metric:
sc.pp.highly_variable_genes(
adata,
n_top_genes=5000,
subset=True,
flavor='seurat_v3',
batch_key="dataset",
)
scvi.model.SCVI.setup_anndata(
adata,
categorical_covariate_keys=['dataset', 'sample_name'],
continuous_covariate_keys=['pct_counts_mt']
)
scvi_tuner = autotune.ModelTuner(scvi.model.SCVI)
search_space = {
"n_hidden": tune.choice([128, 256, 512]),
"n_layers": tune.choice([1, 3, 5]),
"n_latent": tune.choice([10, 20, 30]),
"batch_size": tune.choice([128, 256, 512]),
"lr": tune.loguniform(1e-4, 1e-2),
}
ray.init(log_to_driver=False)
results = scvi_tuner.fit(
adata,
metric='validation_loss',
search_space=search_space,
num_samples=100,
max_epochs=50,
resources={'cpu': 4, 'gpu': 1},
)
I then followed the Ray Tune docs and plotted the “validation_loss” for each experiment:

They pretty much all go up. That seemed weird, but I trained the model with the best params anyway for more epochs. The validation loss indeed goes up:

But I’ve seen in some scverse tutorial that “elbo_validation” and “elbo_train” are used to assess the convergence:
with rc_context({'figure.figsize': (8, 6)}):
elbo_train_set = model.history["elbo_train"]["elbo_train"]
elbo_val_set = model.history["elbo_validation"]["elbo_validation"]
x = np.linspace(0, n_epochs, (len(elbo_train_set)))
plt.plot(x, elbo_train_set, label="train")
plt.plot(x, elbo_val_set, label="val")
plt.show()
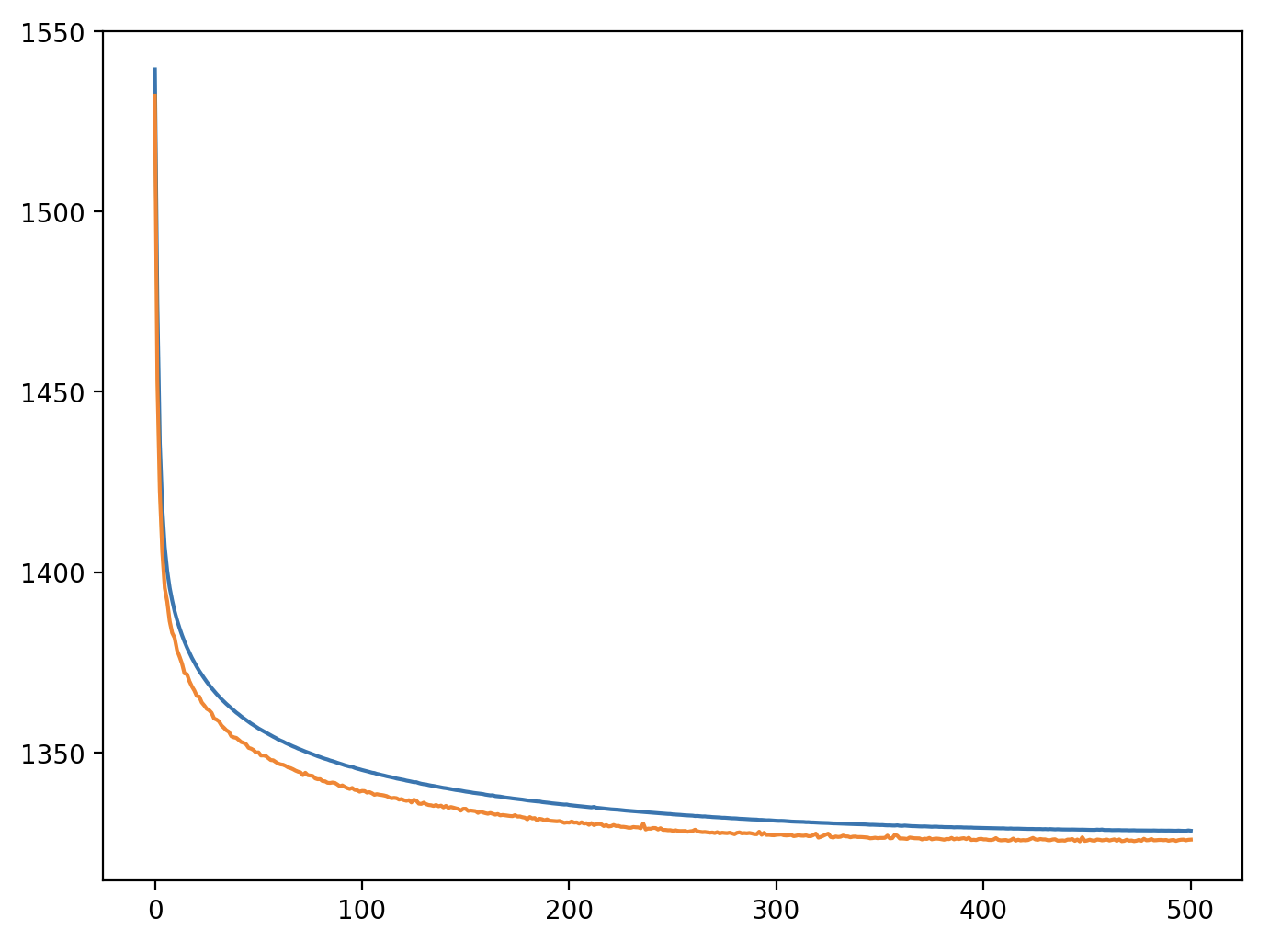
And this one goes down, as I’ve seen in the tutorials.
I’d appreciate any hint on how to understand what’s going on here. Thanks in advance!