Dear Community,
I’m currently working on integrating a single-cell RNA-seq dataset of human mesenchymal stem cells (MSCs) using scvi-tools. The dataset includes 11 samples, each from a different donor, across four tissue types:
- A: Adipose (A01–A03)
- B: Bone marrow (B01–B03)
- D: Dermis (D01–D03)
- U: Umbilical cord (U01–U02)
Each sample corresponds to one patient, so I’ve been using the sample ID (e.g., A01, B02) as the batch_key in SCVI.setup_anndata.
My goal is to mitigate donor-specific batch effects within each tissue, but preserve the biological differences between tissues (since tissue-of-origin is an important axis of variation here).
I’ve followed the scvi-tools tutorials, but after integration, the tissue-specific structure seems to be partially lost.
My Questions:
- Is using
batch_key='Sample' the right approach here?
- Should I treat tissue type as a
categorical_covariate instead, to help scVI retain inter-organ differences?
- Has anyone dealt with a similar situation where batch effects should be removed within groups but preserved between groups?
Any advice or best practices for this type of integration would be greatly appreciated!
Thanks in advance!
You can try the 2nd option, although I think it will just integrate your tissue type as well.
Can you share UMAPs? Or why do you say that “the tissue-specific structure seems to be partially lost”.
Can you share more info on your data? its size? Maybe a stratification issue? Is there any other information that can help in batch integration besides donor (e.g are donors from different studies or do some overlap?, Perhaps sample is not the best choice)
Hi,
Thanks for your response!
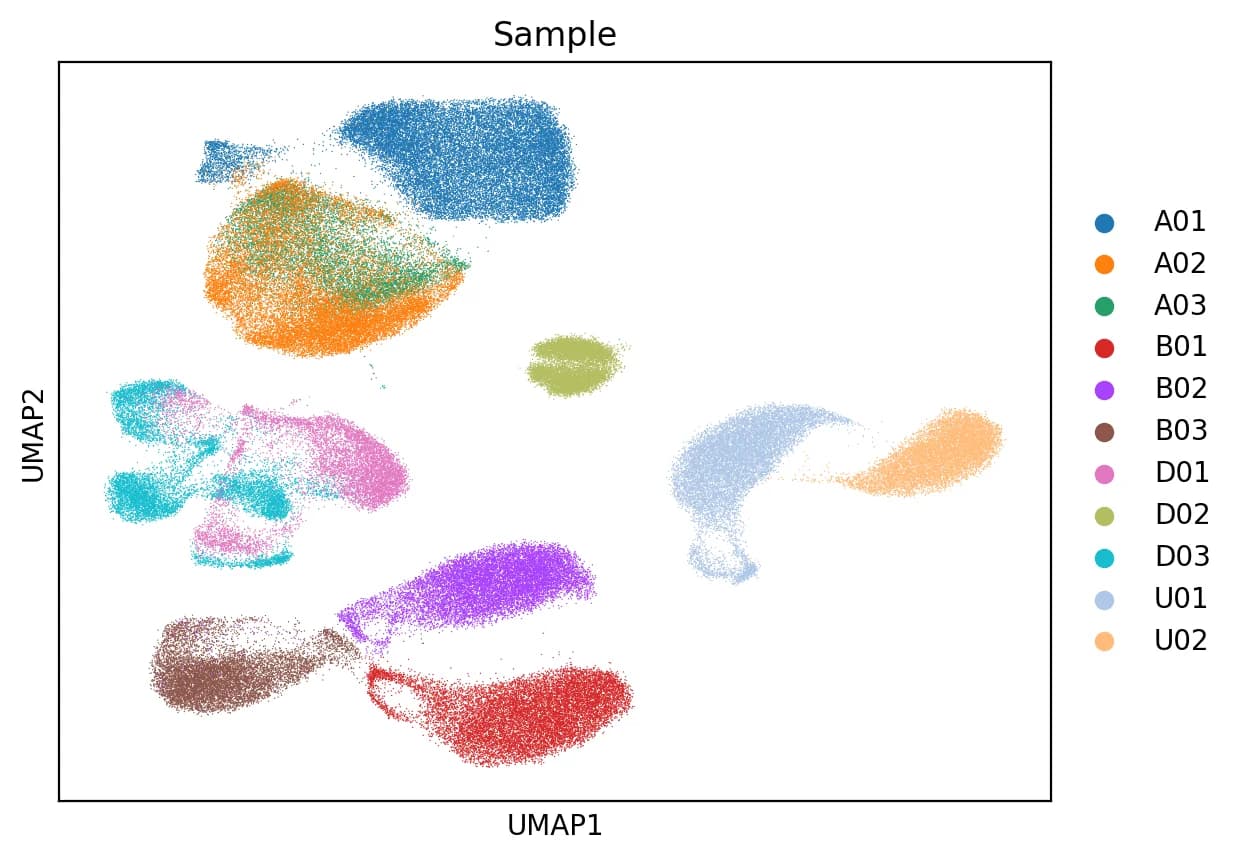
I’d be happy to share my UMAP plots. My dataset consists of 132,706 cells and 33,694 genes. The only metadata I have for each cell is the patient ID and the organ from which the sample was taken.
Please let me know if you need any more details.
Best regards
I guess the 2nd image is with the tissue as a covariate.
Re the 1st figure, can it be that A02 & A03 are from same study and A01 is from a different place?
Same goes for D01 & D03 vs. D02?
How do training/validation loss curves look?
Have you tried other models than SCVI? SysVI or MrVI?
Thank you for your feedback!
The second image shows the result using only Sample as the batch correction variable. All samples are from the same study.
The training and validation loss curves behave normally, with no signs of overfitting or divergence.
I haven’t tried other models yet, if you have any recommendations, I’d be happy to explore them!
Yes, you might try ScanVI (with tissue types as labels) or SysVI or MrVI, in the same manner.
What makes you say the 1st image doesnt preserve biological difference? It’s not that bad… maybe its the best you could do with SCVI.