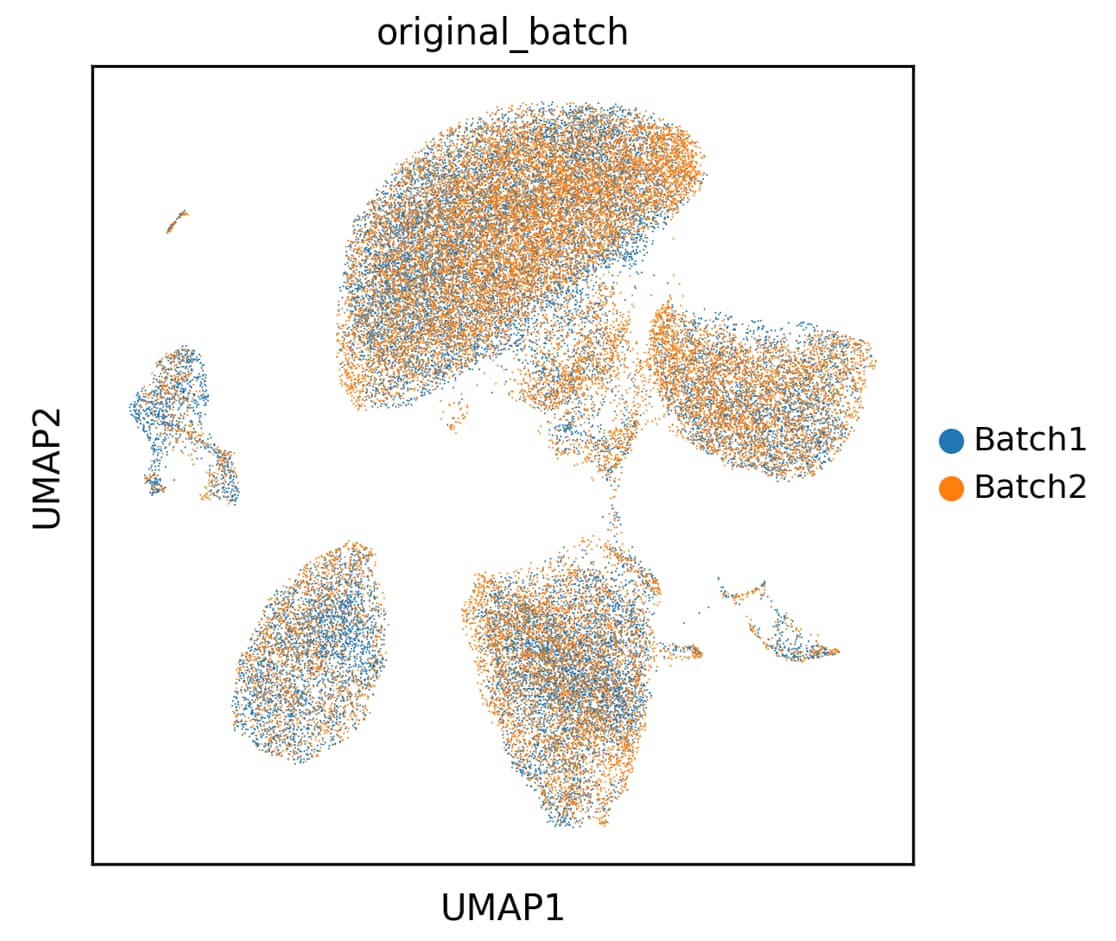
I am working on a data where the data was acquired at an interval of 2-3 years, probably with some differences in the processing kits. Suppose this is represented by “original_batch” ( having two values : Batch1 and Batch2). Other than that, overall the data has 8 patients ( 4 belonging to one condition and 4 belonging to other condition).
I performed integration using scVI and using the “sample” as batch key ( representing overall 8 batches). While that performed pretty well, if I view “original_batch” on the UMAP, it seems there are still some batch effect, which originally i didn’t correct for.
Is it possible to correct this as well or supply two batch keys? While I also think that at a broader level, the 2 batches are roughly equally represented in the clusters. What might be the better way of doing this?
Hi @dub2s, this seems like a good use case for MrVI, which learns one latent space that is sample-aware and batch corrected and another latent space that is just batch corrected. For your data, I’m guessing the batch would be the original batch and the sample would be the experimental condition.
cc @Justin_Hong, one of the main developers of this method
Hi @dub2s, Thanks for the post. Solely for integration you can try using the extra_categorical_covariates feature in scVI to improve mixing. It does look like your UMAP has the issue where your batches are ordered in the data and as a result Batch2 looks much more apparent than Batch1 specifically because the plotting follows the data order. If you shuffle the rows, before plotting it’ll likely give you a better picture of how well it’s mixing. A metric-like silhouette can also give you a more objective view.
MrVI is also an option as Martin suggested. For solely integration the current version may not be better than scVI; you instead get more interesting options for sample-sample analysis. We are working on a new version which we have found improves integration and has many more meta-analysis features. Keep an eye out for this work!
@martinkim0 and @Justin_Hong Thank you for the heads up on MrVI. I will wait for the future releases.
@Justin_Hong I didn’t know about extra_categorical_covariates in scVI. I will use it and update if that improves the mixing. I also plotted proportion of the two batches in each cluster and that looked fairly equal except for one or two clusters.
Hii, I just happened to try harmony as well for the integration, and for this particular dataset, it does look like that it is correcting for the batch effect better, even though I supplied the same “sample” as the batch key.